

Not just SQL - Episode 2
Data Radar, More than just coding, Creator Update and, of course, random things I've read on the internet

The cold winter is here in the Northern Hemisphere, but here’s a very warm ‘Welcome!’ to the second issue of Not Just SQL. It might have taken a while to write it out (busy month, right?), but here’s the latest I wanted to share with you. Let’s dig in!

Exploring SQLMesh - a dbt challenger?
Working in Data Analytics has definitely changed a lot since I first started almost a decade ago. SQL queries are now hopefully saved less often in text files and emailed. Businesses need shorter data-to-insights turnaround, better monitoring, data quality controls they can trust and of course, a better experience for the Analytics staff. This has, in turn, led to an explosion of different projects and products looking to solve a particular pain point.
One such competitive space is the data transformation framework. The elephant in the room in of course dbt, whose mother company dbt Labs is currently valued at multiple billions. There’s also Dataform, acquired by Google and integrated in the their cloud platform.
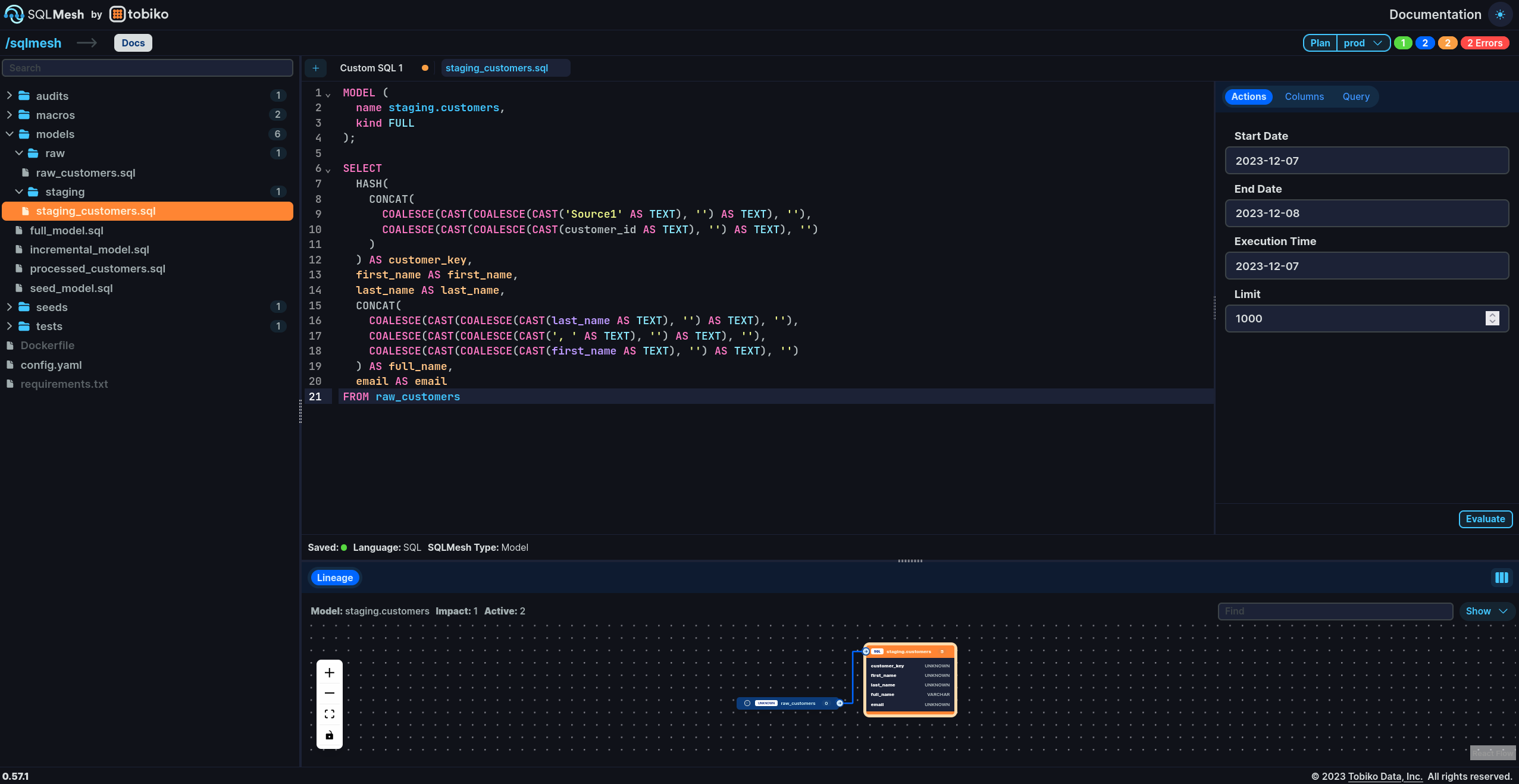
One new player on the block is SQLMesh. It has a number of very interesting promises, some that could be regarded as differentiators.
A BIG accent on DataOps: it surely looks like this tool was built by practicing Data Engineers. Easiness of managing different environments, a Terraform-like “plan-apply” workflow to assess and apply changes, attention to concepts like incremental loading are just some of the features that stand out.
No-copy virtual environments, which I understand Snowflake also has. This means that you not longer need to have multiple *physical* copies of the same data across environments, thus saving storage costs.
A semantic understanding of SQL, built with SQLglot which transpiles i.e. ‘translates’ it, rather than just generates the SQL code based on a template. This allows it to distinguish between breaking and non-breaking changes (think removing a column that is used by downstream models versus removing a unused one), while also allowing for flexibility to work across SQL dialects.
Table and column lineage: one of the most common current requirements to Modern Data stack products.
I’ve decided to try it out using this quickstart guide. The example project was using DuckDB as an analytical database, a pairing I appreciate. For starters, I’ve read a parquet file from a PostgreSQL instance, transforming the data using several steps in a pipeline.
One can use the tool with the built-in UI or the cli, and it offers an adapter to use with existing dbt models (with some changes).
The Slack community is active and was able to assist me quickly when I had questions.
While the tool is under active development and has some rough edges, it’s definitely something to keep an eye on. As with any domain, competition is very healthy for everyone involved.
If you’d like find out more, a very interesting analysis comparing three such solutions (two of which are DBT and SQLMesh, can be found below.

Data radar
Here’s a some more interesting projects I’ve encountered in the past few weeks.
Datadiff
As a Data Engineer, an important challenge in my work is mitigating risk as part of change management. One of the main goals there is avoiding regressions. This is typically in the form of sanity checks - think queries that would compare the state before and after changes: row counts, count of unique keys, ensuring grain alignment with the requirements, corner cases.
I’ve recently stumbled upon Datadiff by Datafold, an automated regression testing tool, as illustrated in this nice blog post. Deploy it as part of your CI/CD pipeline to get these automated checks.
Malloy
Courtesy to the Lindy effect, SQL has, in my humble opinion, quite a long lifetime ahead of it. Its low barrier of entry, ubiquity and long history (hello, late 1970s) give it quite a gravitational pull. That does not stop people from thinking about alternatives though.
I’ve recently discovered Malloy, an open-source language specifically designed to perform data processing tasks. It can of course translate to SQL. Here’s a taste of how it looks and the equivalent SQL.
Queries reproduced from Malloy github page.
run: bigquery.table('malloy-data.faa.flights') -> {
where: origin ? 'SFO'
group_by: carrier
aggregate:
flight_count is count()
average_flight_time is flight_time.avg()
}SELECT
carrier,
COUNT(*) as flight_count,
AVG(flight_time) as average_flight_time
FROM `malloy-data.faa.flights`
WHERE origin = 'SFO'
GROUP BY carrier
ORDER BY flight_count desc
-- malloy automatically orders by the first aggregateTurntable
Does the phrase “how the tables have turned” qualify as SQL joke? You know, like that one with the tables being joined in bar? I’ve also discovered that a turntable is the device that plays vinyls.
On a more serious note though, Turntables is a startup promising to speed up data pipeline creation and management using AI. What caught my eye though, is their free VSCode extension, catering to dbt core users.
It offers no less that column-level lineage, an AI-powered docs auto-filling and model validation before you actually run it. Definitely trying this one.
More than just coding
Tech conference organizers create fake female speakers to increase appearance of diversity
Gergely Orosz’s new book - The Software Engineer’s Guidebook
How saying healthy ‘NO’s can be help you get ahead

Creator update
Searching for a palatable monetization strategy
As a novice content creator, ever since I’ve started writing on a consistent basis, I also pay attention to how other people in tech/data space do it.
There seems to be an ever increasing number of people entering the game. Creating tech content can be quite resource-intensive, so it’s only normal that a lot of people with a consistent following are trying to sell you something. A course or bootcamp, a book, 1-on-1 mentoring sessions. But the important part here is how are they doing it.
How do you create a more palatable monetization strategy? Something that will allow you to earn (or supplement) your livelihood but not disappoint your audience as a creator.
A couple of days ago, I’ve read an interesting post about how an appropriate monetization strategy should look like.
If had to define my stand, I’d say:
the creator should continue to offer good value for people not willing or not being able to pay (also because, in the attention economy, it’s might be the right business decision)
paid products or content should be accessible to people at different price points, based on how deep they’d like to engage (the author of the above post mentions a guide → paid community → in-person retreat structure as an example) and afford to spend
some things of course should be non-negotiable, such as having your audience best interests at heart and not promoting something that you deem immoral or harmful in any way.
This is, of course, a page still to be written for me, but I think it’s beneficial to think about these things beforehand. What would your ideal strategy be?
Tools I use as a content creator
As you may already know, in addition to this page and Linkedin, I publish on Datawise and cross-post on Data Engineer’s Notes, a Medium publication I run.
Content creators use a wide array of tools to get their job done. Now, nobody shared these with me, but I’ve seen a lot of people using them, so I’d like to share a rough list of things I use to help me create content.
Plan:
Notion for taking notes and writing down ideas for future posts. I’m definitely using it for less than it can.
Design:
Canva: a free graphic design tool, useful to create slides, graphs and carousel posts for Linkedin
I’m showcasing a lot of queries to illustrate SQL concepts, snippets which I beautify with Ray and Carbon (pick one that suits you best).
For presenting tables (typically snippet output), I’m copying the query output as JSON and using a converter to create an ASCII table. This then goes into one of the beautifiers from the previous point. Sadly this doesn’t work with STRUCTS/ARRAYS, so the last resort is taking a screenshot of it.
Analyze:
Sadly Linkedin does not provide a straightforward way to know the exact hour something was posted, so you need a specialized tool to extract the timestamp when a particular piece of content was posted for your analytics.
Content Recap
Here’s an overview of my articles posted on Datawise since the last issue of Not Just SQL.
SQL 📰
Python
Not really about tech
Here are some things that are not at all related to computers but which I found interesting.
Flywheel energy storage - an energy storage principle powering kids’ friction toys and many other things
A mild controversy over one of my favorite drinks and what are tea blends
The hoop snake - a legendary creature from English-speaking folklore
One word origin, different stories: Behemoth , Bahamut and hippos
Hope you’ve enjoyed this issue of Not Just SQL! I would appreciate your feedback and, should you find it useful, share it to your network so that the next issue appears sooner.
Thank you!